
PhD AI Expert with 7+ years of experience in academic and industrial R&D. I work on ML/DL methods for computer vision, NLP, and multimodal systems, focusing on trustworthy AI, including safety validation, model robustness, and interpretability. I have contributed to safety-critical applications (autonomous driving, remote sensing) and delivered both research outputs and production-ready solutions. Experienced in supervising students and PhD candidates, leading research projects, and driving collaborative grant proposals.
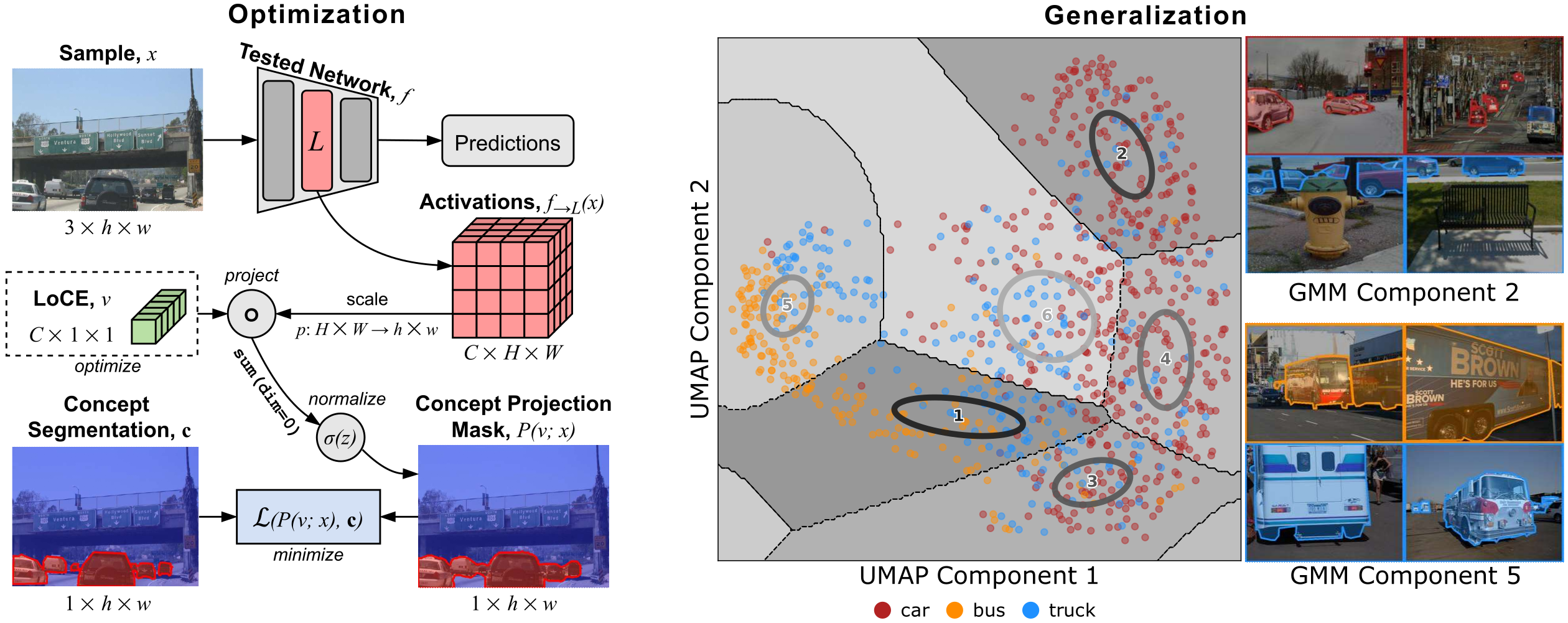
LoCEs (Local Concept Embeddings) provide a way to analyze how DNNs represent object concepts in complex, real-world scenes. Unlike traditional global approaches, LoCEs generate sample-specific embeddings that capture both the target object and its surrounding context within a single, compact representation.
This context-aware analysis helps uncover how models encode, separate, and confuse visual concepts across diverse scenarios. LoCEs reveal meaningful patterns in feature space, supporting model inspection, debugging, and evaluation.
Use cases include:
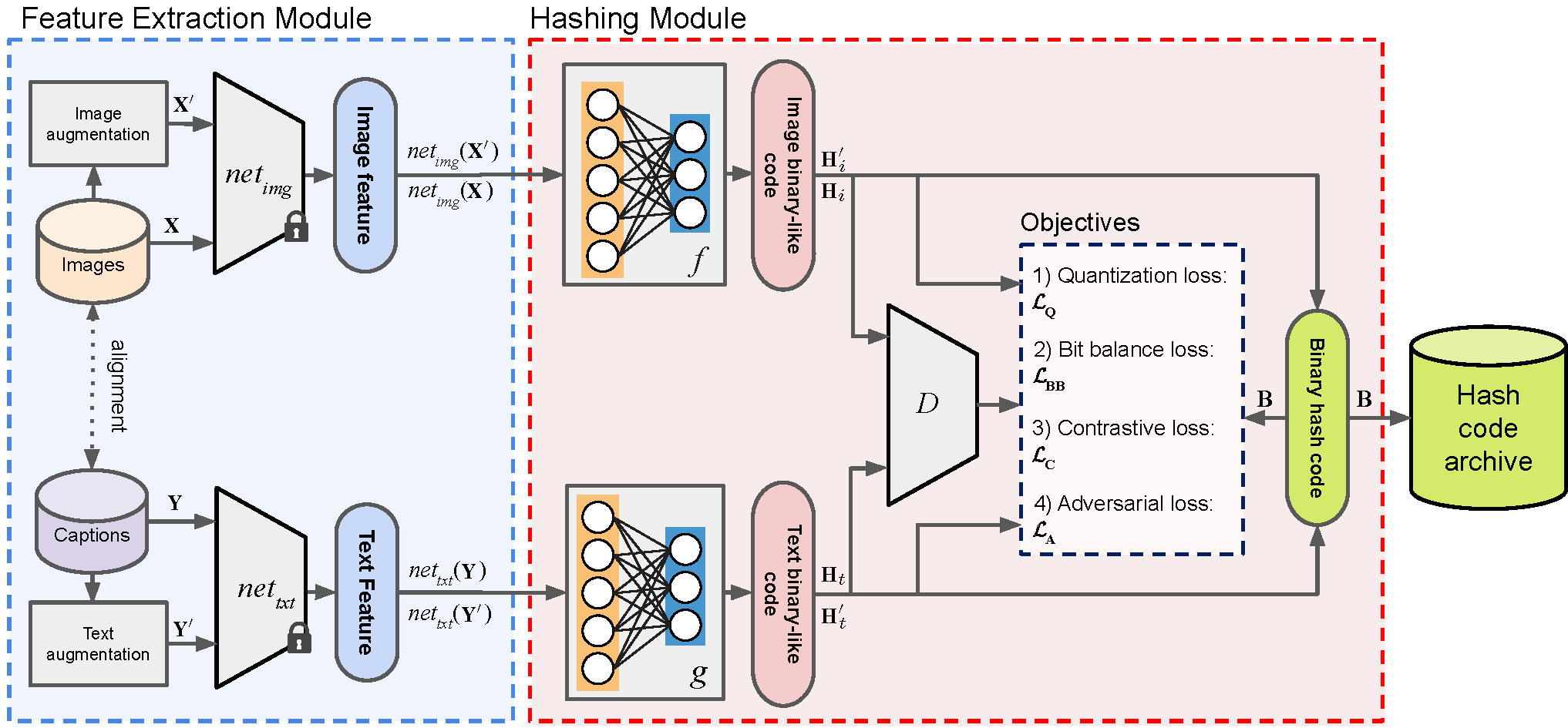
DUCH (Deep Unsupervised Contrastive Hashing) is an unsupervised cross-modal retrieval method designed for efficient search and retrieval of semantically related images and text in large-scale datasets. Unlike traditional supervised retrieval methods that rely on extensive labeled data, DUCH learns discriminative feature representations in an unsupervised manner, making it scalable and adaptable for various multi-modal applications.
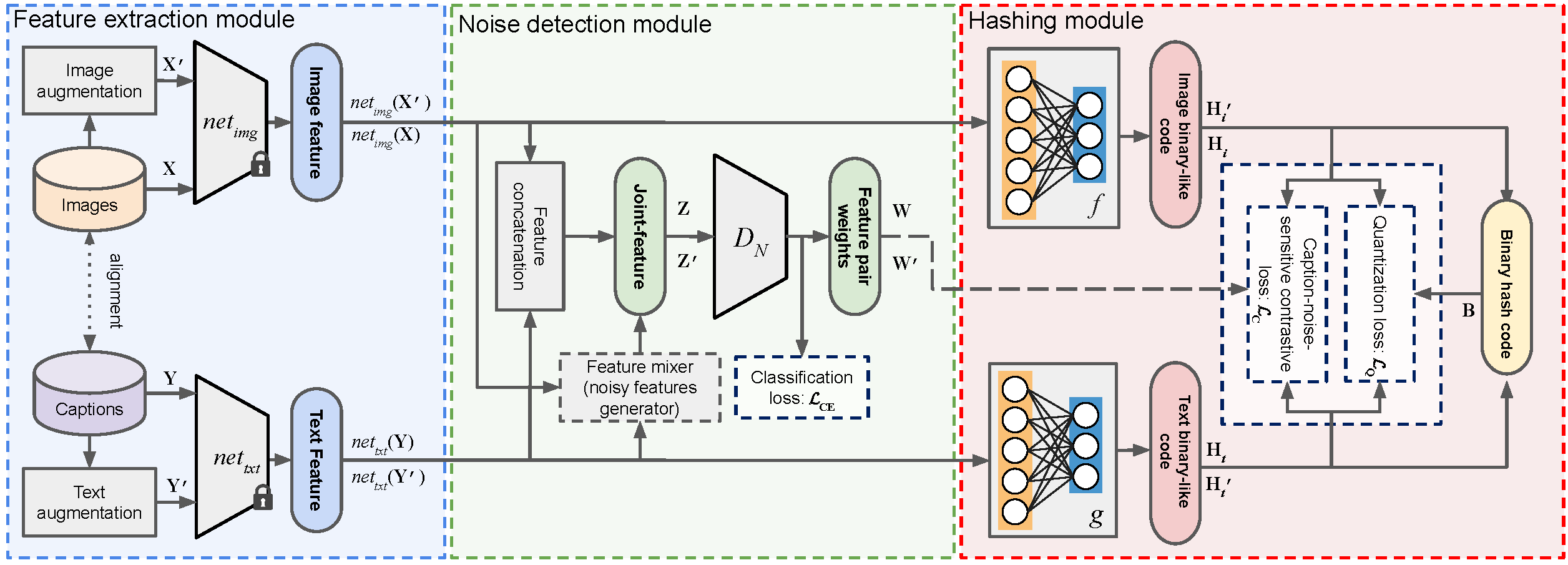
CHNR (Cross-Modal Hashing with Noise Robustness) is an unsupervised technique designed for retrieving images based on textual descriptions, even in the presence of noisy image-text correspondences. It extends DUCH (Deep Unsupervised Contrastive Hashing) by introducing a noise detection module that mitigates errors in training data.
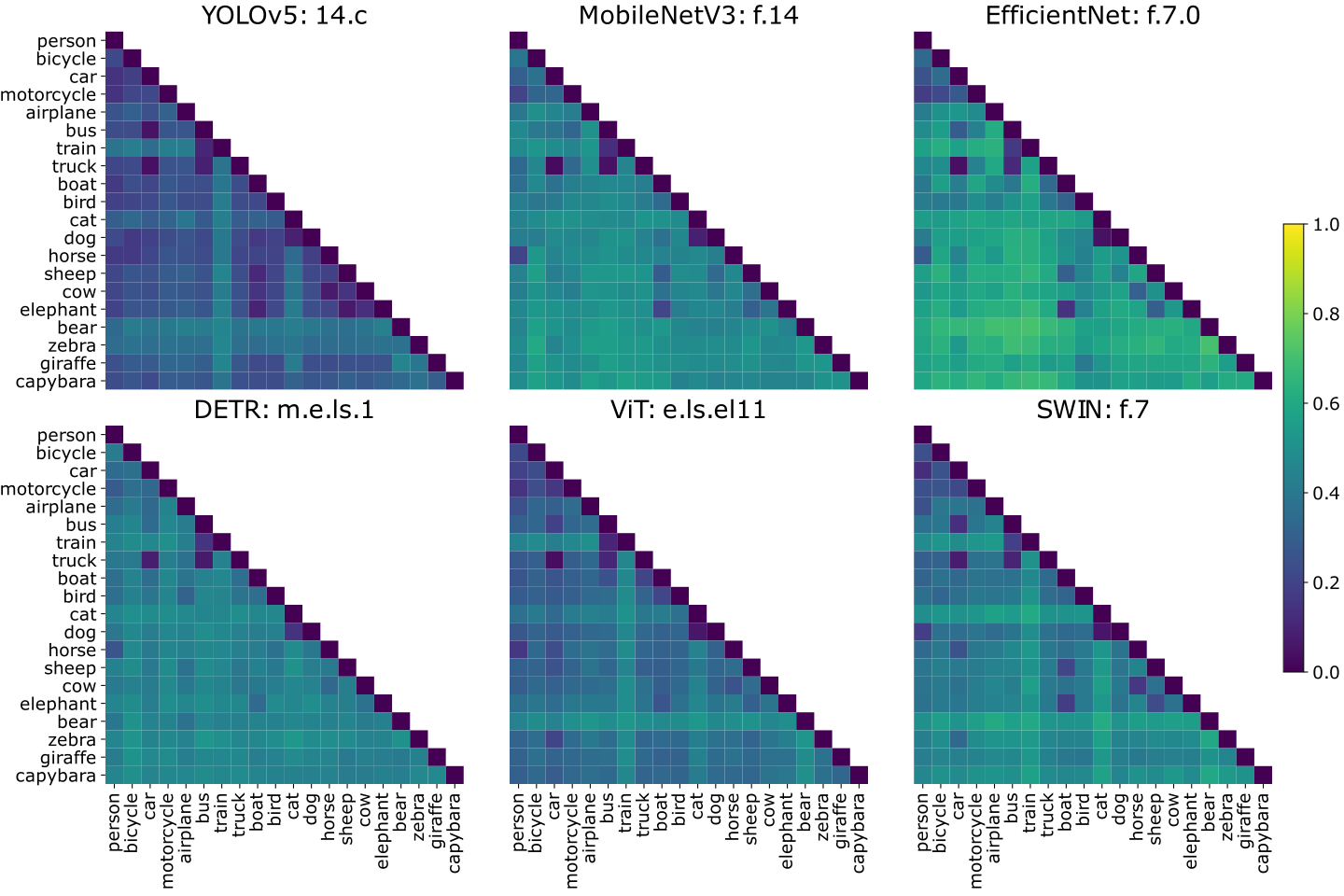
Concept-Based Adversarial Analysis investigates how adversarial attacks manipulate DNNs at the concept level. This study reveals how adversarial attacks distort, introduce, or remove concepts (i.e., latent features) in a model’s feature space.
Through concept discovery techniques, adversarial perturbations are decomposed into components, and their effects are analyzed across multiple DNN architectures and attack types. It is revealed that adversarial attacks systematically distort concept representations, with adversarial perturbations being linearly decomposable into a small set of shared latent vectors. Analysis demonstrates that attack components exploit target-specific directions.

arXiv preprint, 2026.
Gesina Schwalbe, Mert Keser, Moritz Bayerkuhnlein, Edgar Heinert, Annika Mütze, Marvin Keller, Sparsh Tiwari, Georgii Mikriukov, Diedrich Wolter, Jae Hee Lee, Matthias Rottmann.
Explainable Computer Vision @ European Conference on Computer Vision, ECCV 2024.
Jae Hee Lee, Georgii Mikriukov, Gesina Schwalbe, Stefan Wermter, Diedrich Wolter.
Explainable Artificial Intelligence, xAI 2024.
Franz Motzkus, Georgii Mikriukov, Christian Hellert, Ute Schmid.
Explainable Artificial Intelligence, xAI 2024.
Georgii Mikriukov, Gesina Schwalbe, Franz Motzkus, Korinna Bade.
Machine Learning and Principles and Practice of Knowledge Discovery in Databases, ECML PKDD 2023
Georgii Mikriukov, Gesina Schwalbe, Christian Hellert, Korinna Bade.
Explainable Artificial Intelligence, xAI 2023.
Georgii Mikriukov, Gesina Schwalbe, Christian Hellert, Korinna Bade.
Best industry paper award: Awards – The World Conference on eXplainable Artificial Intelligence
EP 4421682 A1
Georgii Mikriukov, Christian Hellert, Erwin Kraft, Gesina Schwalbe.
DE 10 2023 212 859 A1
Georgii Mikriukov, Christian Hellert.
DE 10 2024 200 029 A1
Erwin Kraft, Gesina Schwalbe, Christian Hellert, Georgii Mikriukov.
DE 10 2023 212 519 A1
Georgii Mikriukov, Christian Hellert, Gesina Schwalbe.